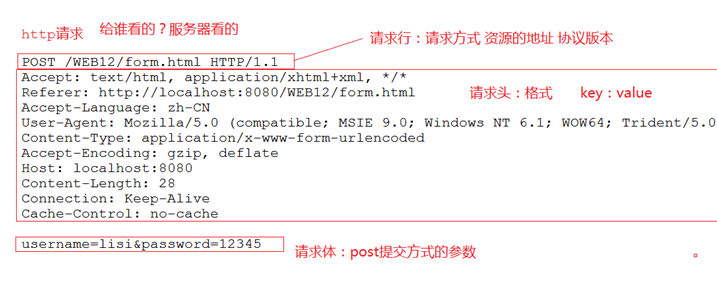
一次完整的HTTP请求过程
域名解析
浏览器会解析url这个域名对应的ip地址
浏览器首先搜索自身的DNS缓存, 看看自身缓存中是否有对应的条目, 如果没有过期, 解析就到此结束.
浏览器自身缓存没有找到对应的条目, 那么chrome浏览器就会搜索操作系统自身的DNS缓存, 如果没有过期则停止搜索, 解析到此结束
浏览器在操作系统中没有找到对应条目, 浏览器会发起一个DNS系统调用, 向本地配置的DNS服务器发起域名解析请求, 这个请求是递归的, 也就是运营商DNS服务器必须给我们提供该IP的地址, 请求过程如下: 运营商DNS服务器首先查找自身的缓存, 如果能在到对应的条目, 且没有过期则解析成功, 如果没有找到对应的条目, 则运营商的DNS代我们的浏览器发送迭代DNS解析请求.
运营商服务器会查找根域服务器的地址, 找到根域的DNS服务, 就会向其发送请求